Context
A friend asked me for headphone recommendations last year. I sent him three links, a Reddit thread, a frequency response chart he didn't know how to read, and a warning about amplifier impedance matching. He bought AirPods Max.
That interaction stuck with me. Not because his choice was wrong — it wasn't — but because the gap between "I want better headphones" and "I understand what I'm buying" is enormous, and nothing out there bridges it well. Recommendation sites push Amazon affiliate links. Reddit threads assume you already know what a "warm V-shaped signature" means. The secondhand market — where the real value lives — is scattered across subreddits, Reverb listings, and Head-Fi classifieds with no way to compare prices or verify deals.
I gave myself two weeks and a Claude Max subscription to see if I could build something better. That was months ago. HiFinder is what it's become.
The Questions
What if finding great headphones took minutes, not hours of research?
Could we cut through conflicting reviews and marketing hype to surface what actually matters — and show the math behind the recommendation?
Could buying secondhand be as easy as buying new?
Most recommendation engines point to retail. What if the secondhand market was the default path, with real pricing data and deal quality indicators built in?
How does complexity unfold as users go deeper?
Headphones are just the entry point. DACs, amps, sound signatures, impedance curves — each layer adds decisions. Can we reveal that complexity progressively rather than overwhelm newcomers?
What I Built
I started with the smallest viable surface area — desktop headphones, clear use case, manageable catalog — and then kept going.
Recommendation Engine
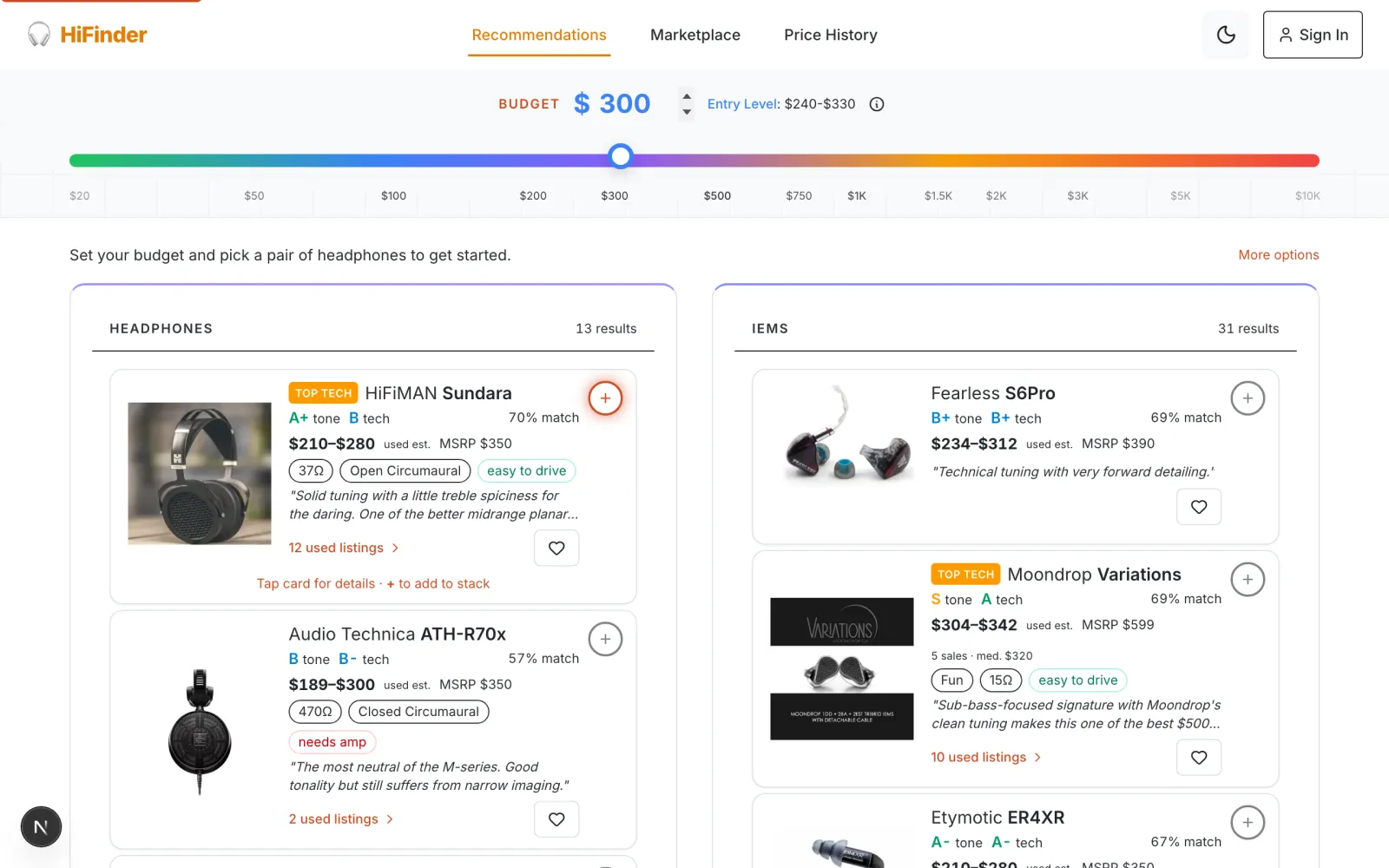
The recommendation algorithm scores components across multiple factors: budget proximity, sound signature matching, amplification difficulty, and a confidence penalty that down-ranks gear with thin data. Users move through five progressive stages — budget, sound signature, amplification needs, compatibility, and review — so they learn something at each step rather than just getting a list.
The results are split into headphones and IEMs side by side, each showing match percentage, used price ranges, Crinacle tone grades, and driveability tags. Tap a card and you get frequency response data, used listings, and the option to add it to a shareable stack.
Shareable stacks generate dynamic OG metadata — meaning the link preview actually shows the component names you picked, not generic site branding.
Marketplace
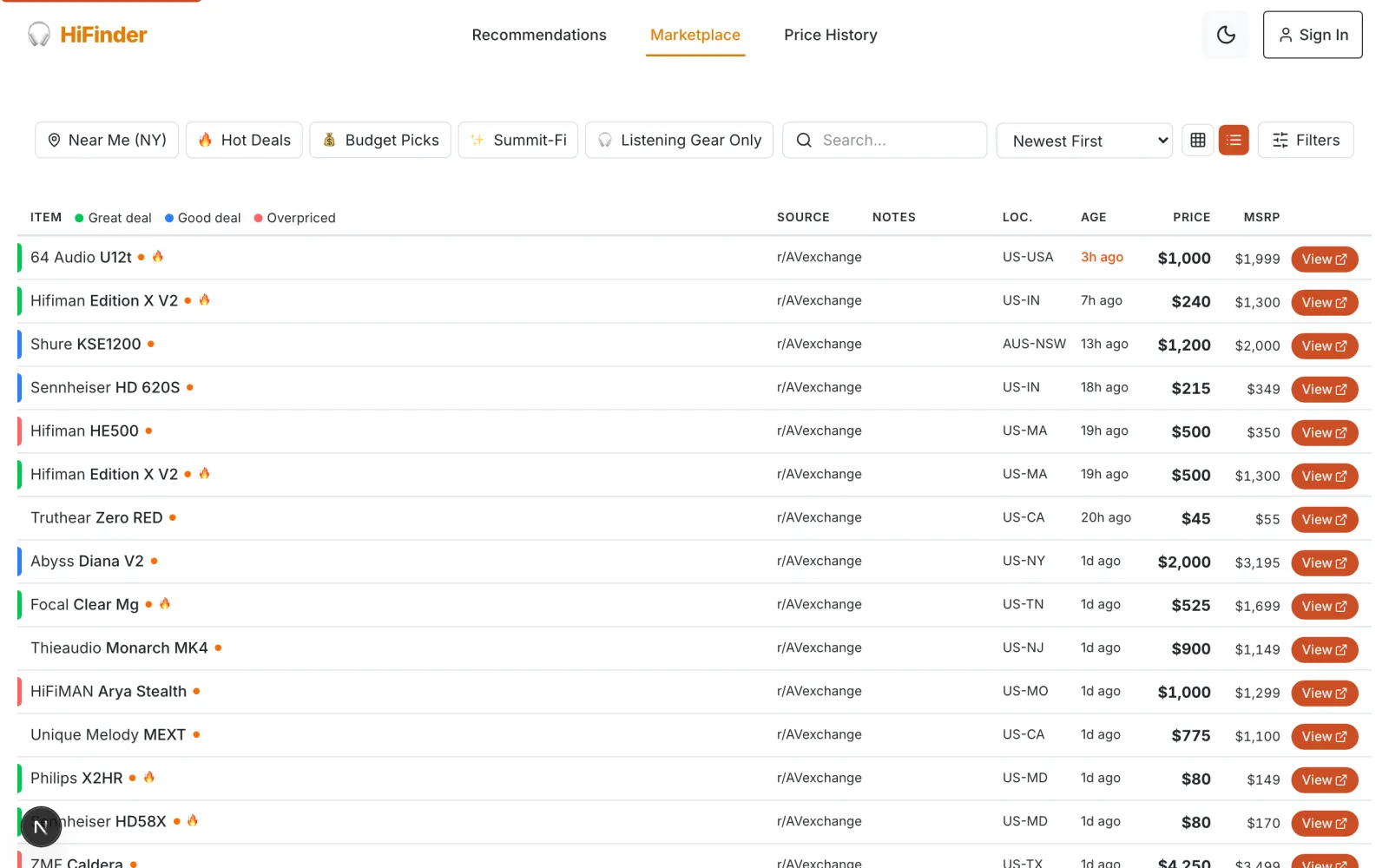
This is where the project got significantly more complex than I expected. The marketplace aggregates used listings from Reddit's r/AVexchange, Reverb, and eBay into a single searchable interface with price-reasonableness scoring.
Each listing gets a color-coded deal indicator — green for below market, yellow for market rate, red for above — based on historical sold data. Users can filter by location (US states, international), quick-filter for hot deals or budget picks, and toggle between grid and list views.
Behind the scenes: a Reddit scraper (now on its third version) tracks AVexchange posts and monitors the confirmation bot for trade verification. A Reverb integration syncs active listings via cron. Listing deduplication catches cross-posts. Price validation flags unreasonable asks. It's a lot of plumbing for what looks like a simple table.
Gear Collection & Stacks
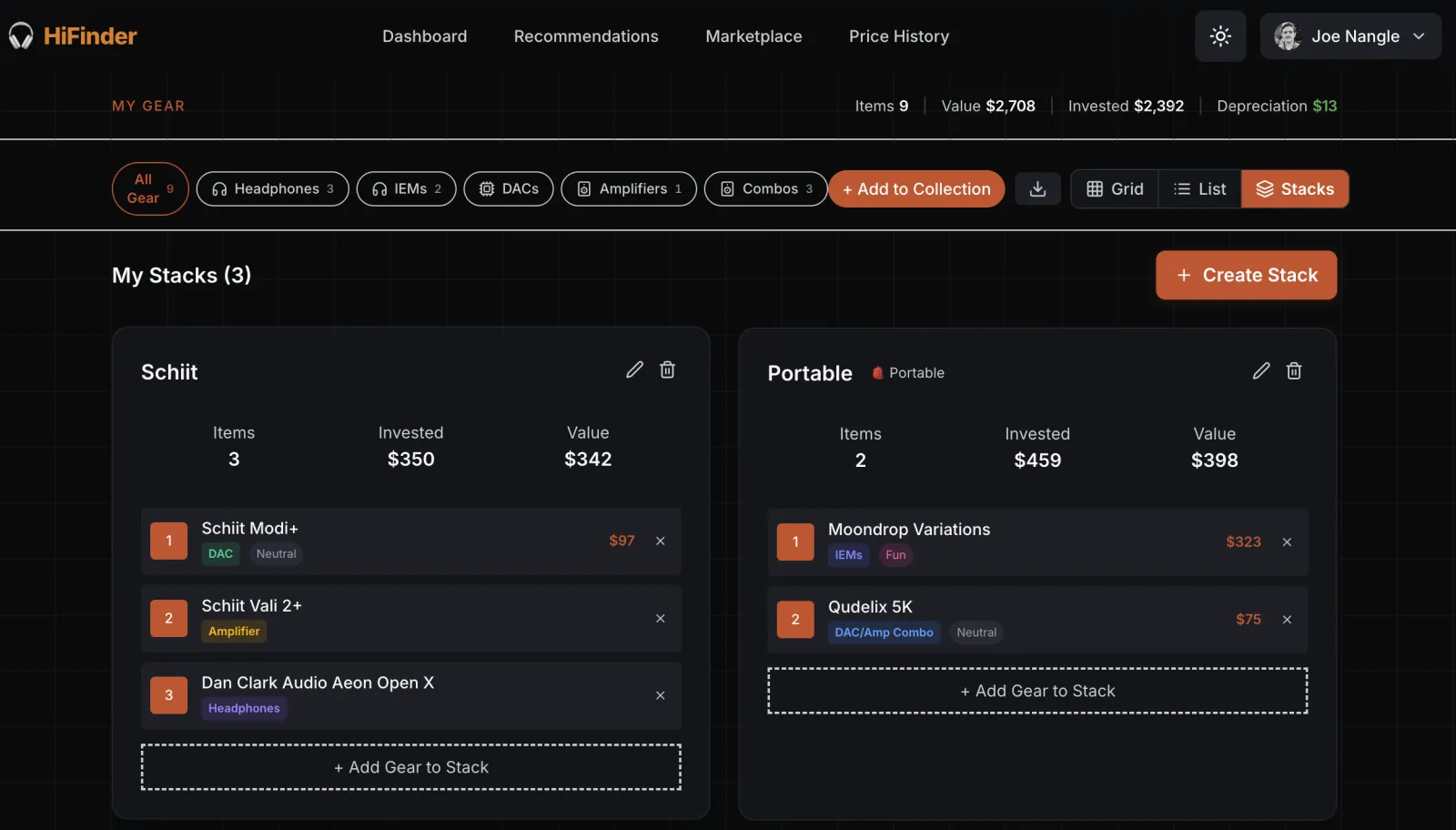
Authenticated users can track their owned equipment with purchase prices and current market values, then organize gear into purpose-based stacks — general listening, portable, reference monitoring, streaming. Each stack shows total investment, current value, and depreciation.
The dashboard ties it together: collection stats, wishlist matches surfaced against live marketplace listings, an upgrade advisor that suggests improvements based on what you already own, and price alerts with server-side matching that emails you when a deal appears.
Learning Hub
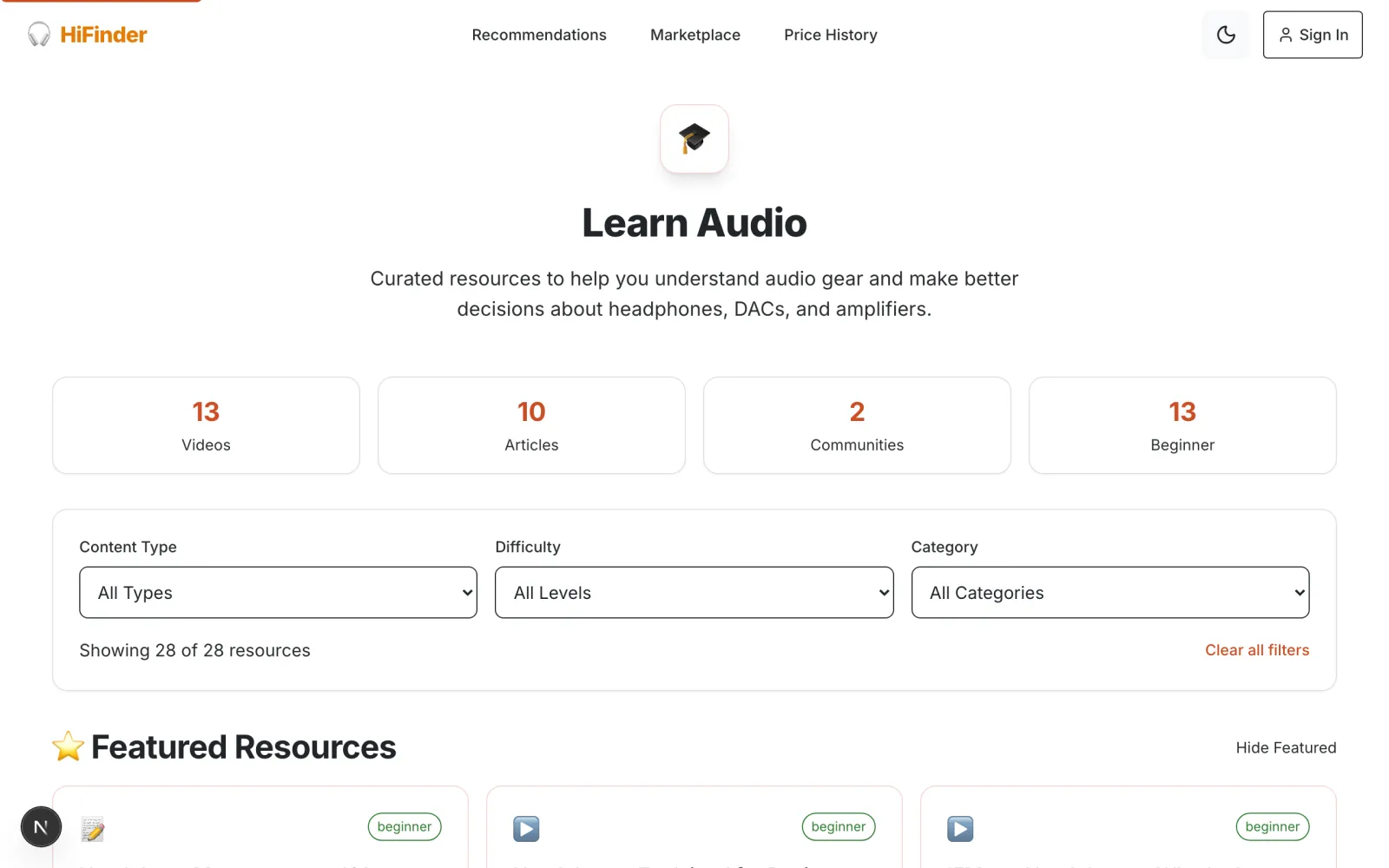
Curated resources — articles, videos, community links — organized by difficulty level and category. This exists because I kept seeing the same questions in r/headphones. Rather than answer each one individually, I built a structured path from "what's a DAC?" to understanding measurement data.
Data Pipeline
The part I'm most proud of isn't user-facing. HiFinder's recommendations are grounded in expert measurement data from two primary sources:
Crinacle rankings and frequency response data — I built a Playwright-based scraper that pulls FR measurements from Crinacle's measurement database, then classifies each headphone's sound signature (warm, neutral, bright, fun, V-shaped, dark) from the actual frequency response curve rather than relying on subjective descriptions.
Audio Science Review SINAD measurements — An OCR pipeline extracts signal-to-noise-and-distortion scores from ASR's dashboard meter images. These measurements ground the amplifier and DAC recommendations in actual performance data rather than marketing specs.
The combination means when HiFinder recommends a $300 headphone as a 70% match, that score reflects real measurements — not aggregated Amazon reviews.
Technical Foundation
- Next.js 16 with App Router and React 19
- Supabase (PostgreSQL, auth, real-time triggers)
- Tailwind CSS v4, Framer Motion
- Vercel deployment with staging environment
- Resend for transactional email
- React Compiler for automatic memoization
- 20+ API routes, 5 data scrapers, server-side alert matching via Postgres triggers
What I've Learned
The scraper is the product. I spent the first two weeks thinking I was building a recommendation engine. I was actually building a data pipeline. The recommendation UI was the easy part — aggregating reliable data from five different marketplace sources, keeping it fresh, deduplicating listings, and validating prices is where all the real complexity lives. I've rewritten the Reddit scraper three times.
Domain knowledge is a cheat code, until it isn't. My years as an audio hobbyist let me move fast on product decisions — I knew which data sources mattered, which specs were marketing noise, and what questions real buyers actually ask. But it also created blind spots. I spent a week building a cable recommendation feature that nobody wanted before catching myself. Knowing the domain doesn't mean you know the user.
Vibecoding has a ceiling, and it's not where I expected. Claude Code got me to a working prototype in two weeks. Getting from prototype to production — handling edge cases, building resilient scrapers, managing database migrations, optimizing Lighthouse scores — that's where the real learning happened. The gap between "it works on my machine" and "it works reliably for strangers" is where I developed genuine technical skill. I went from reading Claude's code to understanding why it made certain architectural choices to occasionally disagreeing with it and being right.
Scope is a feature. The hardest decisions weren't about what to build — they were about what to leave out. I scoped out full-system HiFi configuration, speaker recommendations, a social feed, and a dozen other features that each felt essential in the moment. Every one of those decisions to cut was progress, even when it didn't feel like it.
Status
HiFinder is live at hifinder.app with working recommendation flows, real-time marketplace data, user accounts, and gear management. Current work is focused on:
- User component ratings and community-sourced reviews
- Popular pairing analysis (which DACs get used with which headphones)
- Expanding the product database and filling measurement gaps
- Refining the recommendation algorithm based on usage patterns
I'm building in public and learning as I go. The project started as a two-week experiment and has become something I use every day — which, for a side project, might be the only metric that matters.